Generating Correlated Random Numbers in R Using Matrix Methods
R
Statistics
Simulation
Published
March 19, 2024
Generating random data with a specific correlation structure is a common need in statistical simulation. In this post, let’s walk through how to do it in R using matrix decomposition methods.
The resulting new_random matrix contains values exhibiting approximately the target correlation structure.
Implementation Considerations
Independence
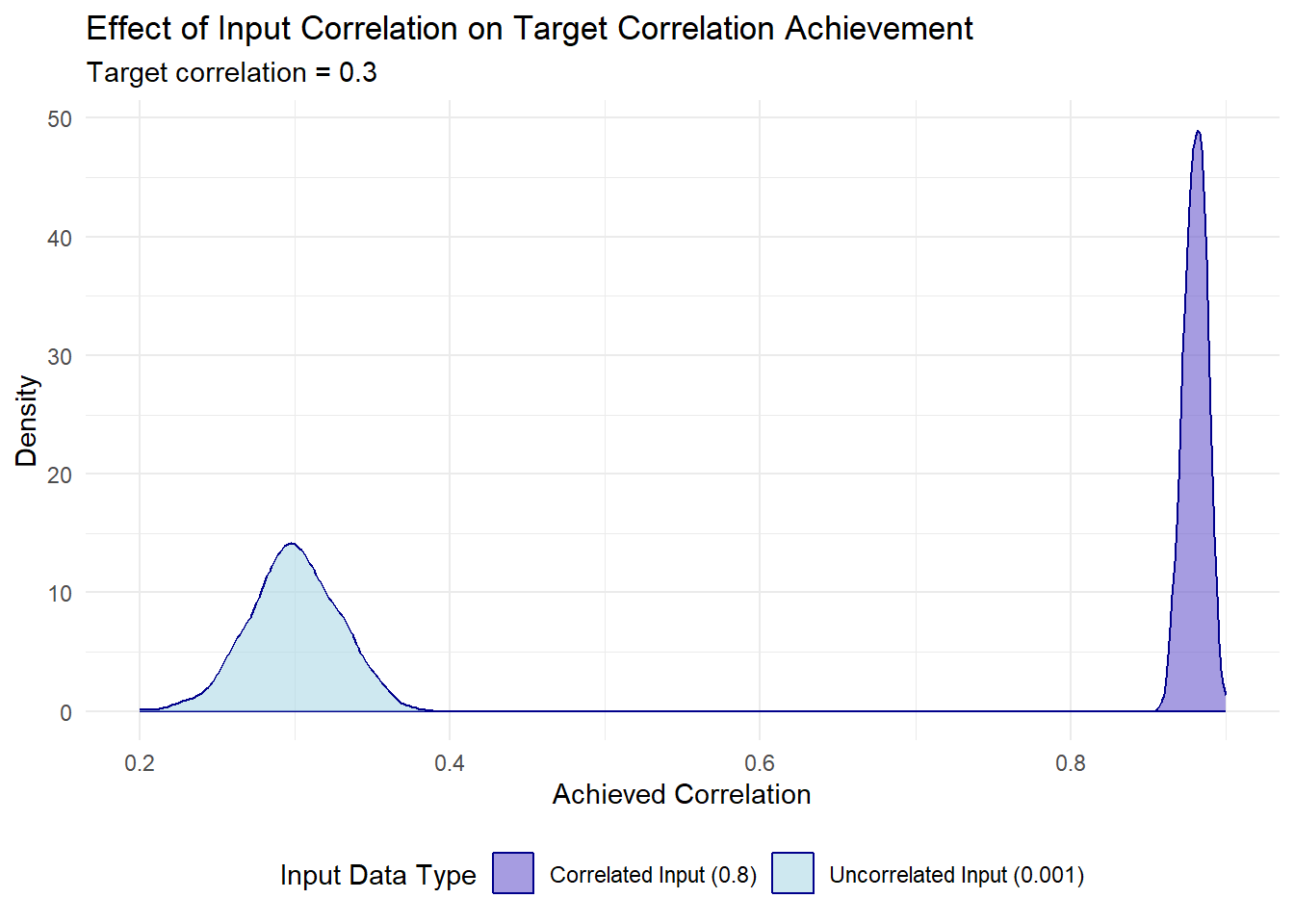
The input data must demonstrate statistical independence for the Cholesky method to function correctly. Pre-existing correlations in the input data compromise the method’s ability to achieve target correlation structures:
# What happens with already correlated input?simulate_correlation <-function(input_correlation, target =0.3) { results <-replicate(1000, {# Create input with specified correlation x <-rnorm(1000) y <- input_correlation * x +rnorm(1000, sd =sqrt(1- input_correlation^2))# Apply our method old_random <-cbind(x, y) chol_mat <-chol(matrix(c(1, target, target, 1), ncol =2)) new_random <- old_random %*% chol_mat# Return resulting correlationcor(new_random)[1,2] })return(results)}# Compare results with different input correlationscorrelated_results <-simulate_correlation(0.8, target =0.3)uncorrelated_results <-simulate_correlation(0.001, target =0.3)# Create data frame for ggplot2plot_data <-data.frame(correlation =c(correlated_results, uncorrelated_results),input_type =factor(rep(c("Correlated Input (0.8)", "Uncorrelated Input (0.001)"), each =length(correlated_results))))# Create density plot with ggplot2ggplot(plot_data, aes(x = correlation, fill = input_type, color = input_type)) +geom_density(alpha =0.6) +labs(title ="Effect of Input Correlation on Target Correlation Achievement",subtitle ="Target correlation = 0.3",x ="Achieved Correlation",y ="Density",fill ="Input Data Type",color ="Input Data Type") +theme_minimal() +theme(legend.position ="bottom") +scale_fill_manual(values =c("slateblue", "lightblue")) +scale_color_manual(values =c("darkblue", "darkblue"))
When input data contains pre-existing correlation patterns, the Cholesky method cannot effectively override these relationships to establish the desired target correlation structure.
Distribution Consistency
The method works best when all variables share the same marginal distribution. Mixing distributions (e.g. normal with chi-squared) can produce unexpected results:
# Different distributions cause problemsset.seed(123)x1 <-rchisq(1000, df =3) # Chi-squared (skewed)y1 <-rnorm(1000) # Normal (symmetric)old_mixed <-cbind(x1, y1)# Same distribution works betterx2 <-rchisq(1000, df =3)y2 <-rchisq(1000, df =3)old_same <-cbind(x2, y2)# Apply the same transformation to bothchol_mat <-chol(matrix(c(1, 0.7, 0.7, 1), ncol =2))new_mixed <- old_mixed %*% chol_matnew_same <- old_same %*% chol_mat# Compare resultscat("Target correlation: 0.7\n")
cat("Same distribution result:", round(cor(new_same)[1,2], 3))
Same distribution result: 0.699
The combination of different probability distributions (such as normal and chi-squared) can result in unexpected correlation patterns following the Cholesky transformation.
Distribution Properties
The Cholesky transformation may fundamentally alter the statistical properties of the original data:
cat("Transformed data range:", round(range(new_random), 2), "\n")
Transformed data range: -12.81 19.93
cat("Negative values in result:", sum(new_random <0), "out of", length(new_random))
Negative values in result: 488 out of 2000
The Cholesky transformation can fundamentally modify data characteristics, such as introducing negative values into previously positive-only distributions, thereby altering the fundamental nature of the data.
Alternate Implementation: mvtnorm
For practical applications requiring efficient implementation, the mvtnorm package provides a streamlined solution for generating multivariate normal distributions with specified correlation structures:
# Load the packagelibrary(mvtnorm)# Define means and covariance matrixmeans <-c(10, 20) # Mean for each variablesigma <-matrix(c(4, 2, # Covariance matrix2, 3), ncol =2)# See the implied correlationcov2cor(sigma)
# Generate correlated normal data in one stepx <-rmvnorm(n =1000, mean = means, sigma = sigma)# Verify the resultround(cor(x), 3)
[,1] [,2]
[1,] 1.000 0.613
[2,] 0.613 1.000
Key Takeaways
Cholesky decomposition provides a mathematical foundation for transforming uncorrelated data into correlated structures through matrix operations
Input data independence is critical for successful correlation induction; pre-existing correlations compromise the transformation effectiveness
Distribution consistency across variables produces more predictable results — mixing different distributions can lead to unexpected correlation artefacts
The transformation process can alter fundamental data properties, requiring careful consideration of distributional characteristics
The mvtnorm package offers production-ready solutions for multivariate normal data generation with specified correlation structures
Method selection depends on specific requirements: Cholesky for educational and custom applications, mvtnorm for operational efficiency